
PDFのファイル名をリネームして、別名保存するスクリプトを書いたのでメモ。
1日に10件~100件あるPDFをリネームして保存する仕事が発生。
あまりの単純作業のため、どうにか自動化できないかを考えました。
ファイル名は命名規則があったので、かなりやりやすかったです。
AdobeのJavaScriptって全然情報ないんですね・・・。
PDFファイル名の条件とJavaScript
PDFファイル名は以下のような命名規則がありました。
dec-0020201215-0.pdf ( xxx-yyyyyyyyyy-n.pdf )
- 3文字がアルファベット
- 4文字目にハイフン
- 10桁の数字
- 15文字目にハイフン
- 1桁~3桁の数字(連番)
保存したい名前は
n.pdf
のようにする必要がありました。
つまり最後の数字だけにするということ。
じゃあファイル名を分解しようということで、
書いたスクリプトは以下。
var fileName = this.documentFileName;
var str1 = fileName.lastIndexOf(“-“);
var newFile = fileName.substr(str1 + 1);
var aPath = this.path;
var cutPath = aPath.replace(fileName,””);
var saveFile = cutPath + newFile;
this.saveAs(saveFile);
流れはこんな感じです。
- 開いているファイルの名前を取得
- そのファイル名から “-” を見つける
- ファイル名から”-” の位置+1したところを切り出す
- ファイルのフルパスを取得
- フルパスからファイル名を削除
- 現在ファイルを開いている場所と切り出した数字だけの文字を結合
- 元のファイルと同じ場所に数字だけの名前で保存
スクリプト実行
アクションウィザードに登録したJavaScriptを実行します。
連番になっている3つのPDFファイルを選択します。
[開始]ボタンをクリックします。
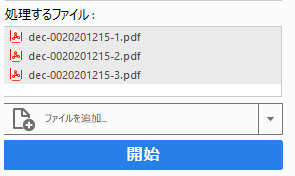
数字だけの名前で保存されました。
this.saveAsはリニアライズ(Web用に最適化)されないようです。
さいごに
この作業を最初は手でやってました。
一つずつ開いて、数字だけ残して、保存押して・・・。
ずっとやっていると、
「一つ前のファイルの数字なんだっけ?」
とか
「今どこやってんの?」
とか、いろいろ分かんなくなってくるんですよ。
実際の作業では上のような分かりやすい数字ではなく、
パッと見て違いがわからないような並びです。
JavaScriptを書いてからは一瞬で終わるし、ミスる要素もないので楽ちんでした。
リニアライズされないことが分かったので没になりましたけどね。
